MCP Agent Hub
A hub that gives AI agents the tools they need and the guardrails to contain them, through the Model Context Protocol.
- MCP
- · Agents
- · Safety
- · Infrastructure
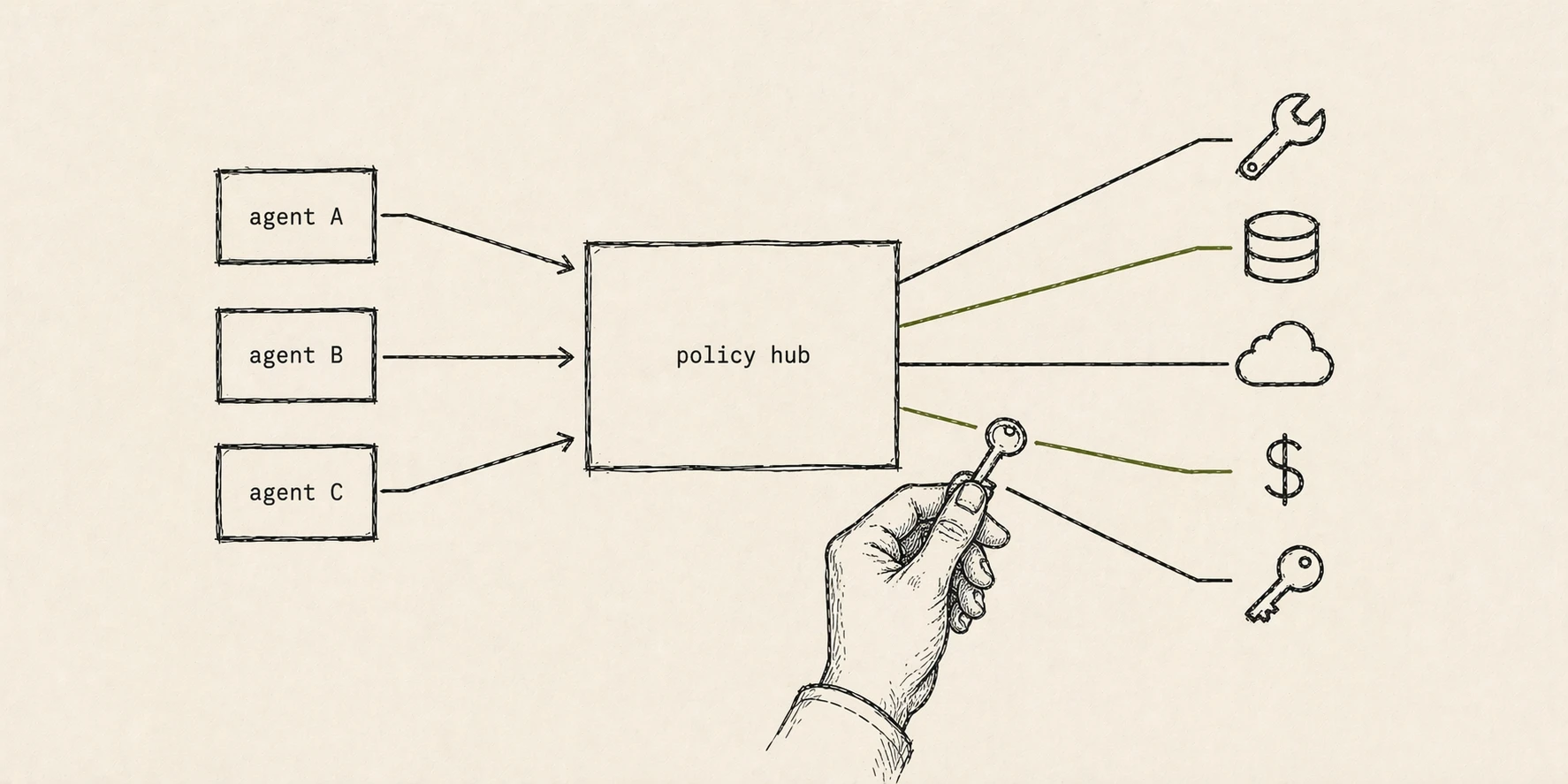
The problem
AI agents only become useful when they can act. The moment they can act, they become a safety problem: prompt injection, tool misuse, runaway loops, data exfiltration. Most teams trying to deploy agents choose between useful-and-risky or safe-and-useless.
The approach
We designed and helped build an MCP-based hub that sits between agents and the real world. Every tool an agent can call is registered, described, and wrapped with policy. Every call is logged, rate-limited, and evaluated against guardrails before it executes.
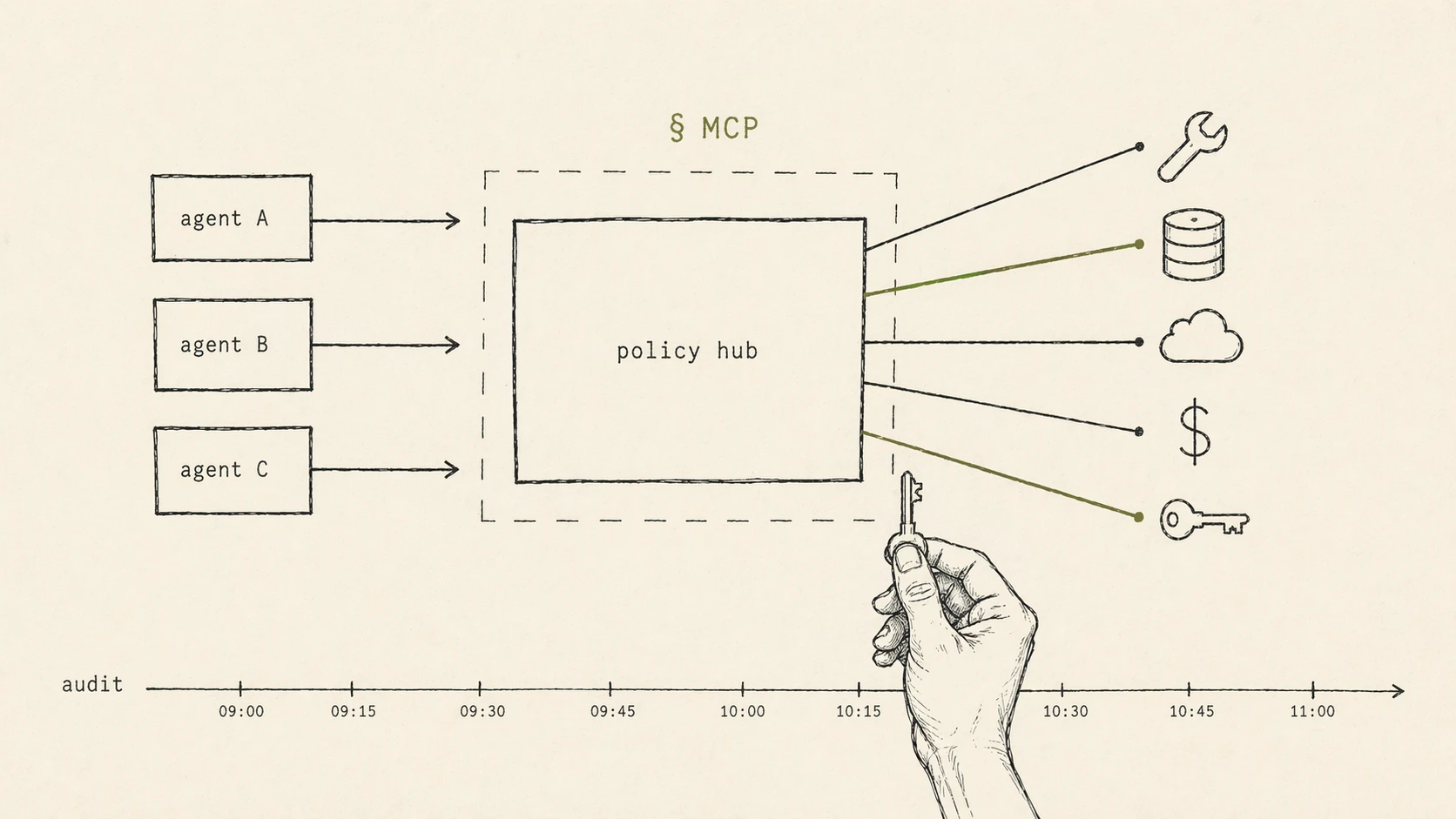
- A registry of tools exposed via Model Context Protocol — one surface agents from any provider can consume.
- Per-agent and per-user policy — which tools are allowed, under what conditions, with what spend or data scope.
- Guardrails at the protocol layer, not the prompt layer — so a jailbroken model still can’t get past the rules.
- An audit stream that makes agent behavior reviewable the same way we review code.
Outcome
Agents become deployable when the infrastructure around them treats them like untrusted clients. The MCP layer is where that trust boundary belongs. Once it’s there, product teams stop arguing about whether to ship agents and start arguing about which ones to ship next.
How we worked
Advisory on architecture and safety posture; product design for the agent-facing UX of tool selection and failure; collaboration with engineering on the registry and policy layer.
Capabilities described here are generalized. We don’t discuss specific client implementations.